BlochSphereV0
Description
BlochSphereV0 is a single-qubit quantum environment intended for teaching, visualization, and simple RL-style control experiments. It is based on the QuantumEnv base class. The environment represents the qubit state on the Bloch sphere and provides a discrete set of quantum gates (Clifford + common rotations) as actions.
The agent’s goal is to steer the qubit from the fixed initial state |0\rangle to a specified target state (by default |+\rangle) within a minimum number of steps.
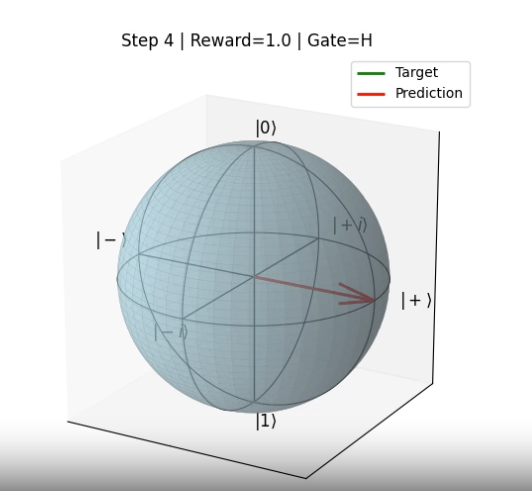
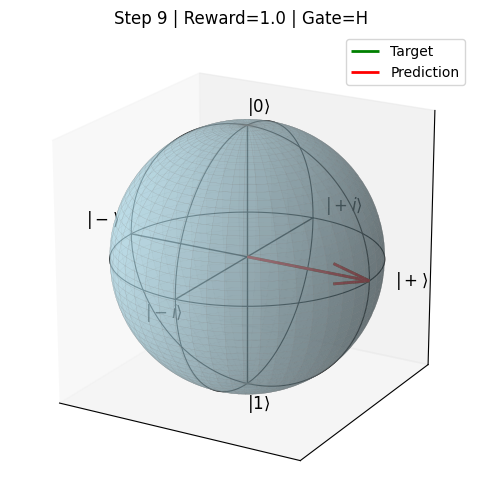
As seen in the Render (see results\core): a semi-transparent Bloch sphere with labeled poles and equatorial points. The green arrow shows the target Bloch vector while the red arrow shows the evolving state (prediction) across steps. The sphere shows solid X, Y, Z axes and circular outlines for the XY, XZ, and YZ planes for visual reference.
Action Space
The action space is discrete.
Each action applies a unitary gate to the current single-qubit state (left-multiplication by its 2x2 unitary matrix). Actions are deterministic and map directly to a fixed gate or rotation.
Num |
Action |
Description |
|---|---|---|
0 |
|
Hadamard gate |
1 |
|
Pauli-X (NOT) |
2 |
|
Pauli-Y |
3 |
|
Pauli-Z |
4 |
|
Phase gate (S) |
5 |
|
S† (S dagger) |
6 |
|
T gate |
7 |
|
T† (T dagger) |
8 |
|
Rotation about X by +π/2 |
9 |
|
Rotation about X by +π/4 |
10 |
|
Rotation about X by -π/4 |
11 |
|
Rotation about Y by +π/2 |
12 |
|
Rotation about Y by +π/4 |
13 |
|
Rotation about Y by -π/4 |
14 |
|
Rotation about Z by +π/2 |
15 |
|
Rotation about Z by +π/4 |
16 |
|
Rotation about Z by -π/4 |
The action_space is a gymnasium.spaces.Discrete(len(actions)) where the integer index selects the action above.
Observation Space
The observation is a 3-dimensional ndarray corresponding to the Bloch vector (x, y, z) of the current pure qubit state. Shape: (3,), dtype float32, with each component bounded in [-1, 1].
Num |
Observation component |
Min |
Max |
Meaning |
|---|---|---|---|---|
0 |
|
-1 |
1 |
2 Re(ρ₀₁) — X component of Bloch vector |
1 |
|
-1 |
1 |
2 Im(ρ₁₀) — Y component of Bloch vector |
2 |
|
-1 |
1 |
ρ₀₀ - ρ₁₁ — Z component of Bloch vector |
Notes:
Internally the environment stores the statevector
|ψ⟩(complex two-component vector) and converts to the Bloch vector for observations using the density matrixρ = |ψ⟩⟨ψ|.
Rewards
Reward is defined as the quantum state fidelity (squared overlap) between the current state and the target state:
reward = |⟨target | state⟩|^2
This produces a continuous reward in [0, 1].
Typical usage in episodic RL: treat higher reward as progress; the environment flags done when reward exceeds reward_tolerance (default 0.99). The environment does not subtract step penalties by default, but users can wrap or modify rewards to encourage shorter trajectories.
Starting State
On reset() the environment:
sets
steps = 0;initializes the qubit to
|0⟩(statevector[1, 0]);sets
historyto contain the initial Bloch vector and metadata('None','None').
By default the target state is |+⟩ = (|0⟩ + |1⟩)/√2 (unless a different target_state is passed to the constructor). The code example in this class shows the target_state argument available in __init__ so users can choose a different target on env construction.
Episode End
An episode terminates (i.e., done=True) when either:
Success / Termination: The fidelity
|⟨target|state⟩|^2is strictly greater thanreward_tolerance(default0.99).Truncation: The number of steps reaches
max_steps(default20).
The step() method returns (observation, reward, done, info) matching gymnasium.Env conventions. info is currently empty but history is stored on the environment instance for inspection and rendering.
Render
render(save_path=None, interval=800) produces a Matplotlib 3D animation visualizing the Bloch sphere, target vector (green), and the recorded state trajectory (red vector updated per frame). If save_path is provided, the animation is saved (FFmpeg writer is used); otherwise the animation is shown with plt.show().
Rendering details:
Sphere is drawn once as a translucent mesh.
X/Y/Z axes are drawn as solid lines and equatorial/circular outlines for XY/XZ/YZ planes are shown.
Labels placed for canonical states:
|0⟩,|1⟩,|+⟩,|−⟩,|+i⟩,|-i⟩.The animation title displays
Step,Reward(rounded), andGateapplied at that step.
Arguments (Constructor & Reset Options)
Constructor signature (as implemented):
BlochSphereV0(target_state, max_steps=20, reward_tolerance=0.99)
target_state: complex 2-vector specifying the target pure state. IfNone, defaults to|+⟩.max_steps: maximum number of actions per episode (truncation threshold).reward_tolerance: fidelity threshold above which the episode is marked successful.ffmpeg: ifTrue, uses FFmpeg for saving animations; otherwise uses Pillow (GIF).
reset() currently ignores an options dict for seeding or custom initialization; this can be extended to allow randomized initial states or alternative targets.
[1]:
### Example -> Stand alone implementation
import numpy as np
from qrl.env import BlochSphereV0
# Target vector is |+> = (|0> + |1>)/sqrt(2)
target_state = np.array([1/np.sqrt(2), 1/np.sqrt(2)])
# Initialize environment
# set ffmpeg=True if you have ffmpeg installed to save as mp4, or ffmpeg=False to save as gif
env = BlochSphereV0(target_state=target_state, max_steps=20, reward_tolerance=0.99, ffmpeg=False)
# Reset
obs, _ = env.reset()
print("Initial Observation (r, theta, phi):", obs)
# Randomly sample actions
for _ in range(env.max_steps):
action = env.action_space.sample()
obs, reward, done, _ = env.step(action)
print(f"After {action} action -> Observation:", obs)
print("Reward:", reward, "Done:", done)
if done:
break
# Render Bloch sphere
env.render(save_path_without_extension="bloch_sphere")
Initial Observation (r, theta, phi): [0. 0. 1.]
After 6 action -> Observation: [0. 0. 1.]
Reward: 0.4999999999999999 Done: False
After 15 action -> Observation: [0. 0. 1.]
Reward: 0.4999999999999999 Done: False
After 3 action -> Observation: [0. 0. 1.]
Reward: 0.4999999999999999 Done: False
After 16 action -> Observation: [0. 0. 1.]
Reward: 0.4999999999999999 Done: False
After 10 action -> Observation: [ 0.0000000e+00 1.2246469e-16 -1.0000000e+00]
Reward: 0.4999999999999999 Done: False
After 5 action -> Observation: [ 1.2246469e-16 0.0000000e+00 -1.0000000e+00]
Reward: 0.4999999999999999 Done: False
After 11 action -> Observation: [-2.4492937e-16 -0.0000000e+00 1.0000000e+00]
Reward: 0.4999999999999998 Done: False
After 3 action -> Observation: [2.4492937e-16 0.0000000e+00 1.0000000e+00]
Reward: 0.5000000000000001 Done: False
After 0 action -> Observation: [1.000000e+00 0.000000e+00 3.330669e-16]
Reward: 0.9999999999999996 Done: True
Implementation Notes & Extensions
The environment expects unitary matrices to be available via a
GATESdict for named Clifford gates and helper functionsRX(theta),RY(theta),RZ(theta)for parameterized rotations. Those helpers should return 2×2 NumPy/Pennylane-arrays that multiply the statevector.Currently the state is pure and represented as a statevector. To support mixed states or noise channels, one could change internal storage to density matrices and adapt
_state_to_blochaccordingly.Reward shaping: to encourage shorter trajectories, add a step penalty (e.g.,
-0.01) or give a sparse success reward on reaching the target.Observation augmentation: include the current step number, recent gate applied, or the fidelity as extra observation channels if training agents that benefit from that information.
Version History
v0: Initial design and implementation. Single-qubit pure-state environment with fixed initial state
|0⟩, discrete gate set, fidelity reward, Matplotlib-based Bloch sphere renderer, and history tracking.
References (Suggested Reading)
Bloch sphere — standard geometric representation for a qubit.
Nielsen, M. A., & Chuang, I. L., Quantum Computation and Quantum Information (for unitary gate definitions and single-qubit geometry).