CompilerV0
Description
The CompilerV0 environment is designed to simulate the task of quantum gate compilation for a single-qubit system. It is based on the QuantumEnv base class. The agent’s goal is to sequentially apply quantum gates to approximate a randomly chosen target unitary operation from the special unitary group SU(2). This mimics a quantum compilation problem where one attempts to rewrite a quantum operation in terms of a limited gate set.
At each step, the agent applies one of several predefined single-qubit gates, evolving the current circuit unitary. The agent receives a reward proportional to the fidelity between the evolved unitary and the target unitary, and the episode terminates when the agent either reaches a sufficiently high fidelity or exhausts the maximum step limit.
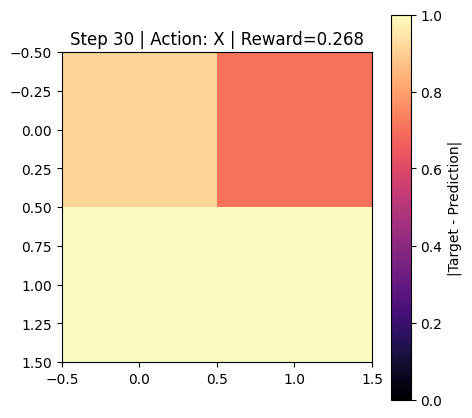
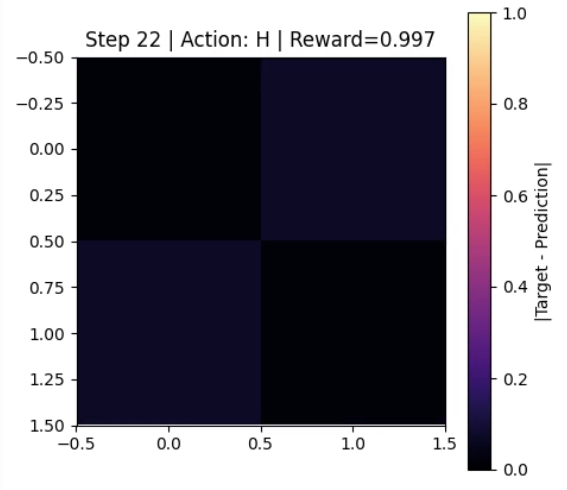
The environment includes a rendering mode that visualizes the difference matrix between the target and the current unitary as a heatmap evolving over time.
Action Space
The action space is discrete, where each action corresponds to applying a quantum gate from a fixed set of single-qubit operations:
Num |
Action |
Description |
|---|---|---|
0 |
|
Hadamard gate |
1 |
|
Pauli-X gate |
2 |
|
Pauli-Y gate |
3 |
|
Pauli-Z gate |
4 |
|
Phase gate |
5 |
|
Conjugate transpose of Phase gate |
6 |
|
π/8 gate |
7 |
|
Conjugate transpose of π/8 gate |
8 |
|
X-axis rotation by π/2 |
9 |
|
X-axis rotation by π/4 |
10 |
|
Y-axis rotation by π/2 |
11 |
|
Y-axis rotation by π/4 |
12 |
|
Z-axis rotation by π/2 |
13 |
|
Z-axis rotation by π/4 |
Observation Space
The observation is a flattened representation of the current unitary matrix, expressed in terms of its real and imaginary parts. This results in an 8-dimensional vector:
Num |
Observation Component |
Range |
|---|---|---|
0-3 |
Real part of unitary |
[-1, 1] |
4-7 |
Imag part of unitary |
[-1, 1] |
This encodes the full (2 \times 2) complex unitary matrix.
Rewards
The reward is based on the average gate fidelity between the target unitary U_{target} and the current unitary U. Specifically:
\(reward = \frac{1}{2} \left| \mathrm{Tr}(U_{target}^\dagger U) \right|\)
A higher reward indicates closer alignment with the target unitary.
The episode terminates early if the reward exceeds
reward_tolerance(default: 0.98).
Starting State
At the start of each episode:
The circuit unitary is initialized as the identity matrix ( I ).
The target unitary is specified by the user at initialization. (By default, this can be drawn from a random U3(θ, φ, λ) decomposition in SU(2).)
The initial observation corresponds to the identity matrix.
Episode End
The episode ends if one of the following occurs:
Termination: The fidelity between the current and target unitary exceeds the reward tolerance (
reward > 0.98by default).Truncation: The number of steps exceeds the maximum episode length (
max_steps, default: 30).
Rendering
The environment supports visualization of the compilation process:
A heatmap is drawn showing the magnitude of the difference matrix: \(|U_{target} - U|\) at each step.
The heatmap updates dynamically, and the plot title displays the step number, last applied gate, and reward.
The animation can be saved as an MP4 file or displayed interactively.
Arguments
``target`` (
np.ndarray): The target (2 \times 2) unitary matrix to compile towards.``max_steps`` (
int, default=30): Maximum number of steps per episode.``reward_tolerance`` (
float, default=0.98): Fidelity threshold for early termination.``ffmpeg`` (
bool, default=False): IfTrue, uses FFmpeg for saving animations; otherwise uses Pillow (GIF).
[1]:
## Example:
import numpy as np
from qrl.env.core.utils import RY, RZ
from qrl.env import CompilerV0
theta, phi, lam = np.random.uniform(0, 2*np.pi, 3)
target = (RZ(phi) @ RY(theta) @ RZ(lam)) # general SU(2)
# Initialize environment with 1 qubit
# set ffmpeg=True if you have ffmpeg installed to save as mp4, or ffmpeg=False to save as gif
env = CompilerV0(target_unitary=target, max_steps=30, reward_tolerance=0.98, ffmpeg=False)
# Reset
obs, _ = env.reset()
print("Initial Circuit State:", obs)
for _ in range(env.max_steps):
action = env.action_space.sample()
obs, reward, done, _ = env.step(action)
print(f"After {action} action -> Observation:", obs)
print("Reward:", reward, "Done:", done)
if done:
break
# Render Bloch sphere
env.render(save_path_without_extension="compilerV0")
Initial Circuit State: [1. 0. 0. 1. 0. 0. 0. 0.]
After 12 action -> Observation: [ 6.123234e-17 0.000000e+00 0.000000e+00 6.123234e-17 -1.000000e+00
0.000000e+00 0.000000e+00 1.000000e+00]
Reward: 0.7632554085856338 Done: False
After 0 action -> Observation: [ 4.3297803e-17 4.3297803e-17 4.3297803e-17 -4.3297803e-17
-7.0710677e-01 7.0710677e-01 -7.0710677e-01 -7.0710677e-01]
Reward: 0.026880376541707558 Done: False
After 13 action -> Observation: [-7.0710677e-01 7.0710677e-01 7.0710677e-01 7.0710677e-01
-8.6595606e-17 0.0000000e+00 0.0000000e+00 -8.6595606e-17]
Reward: 0.9003790168046004 Done: False
After 1 action -> Observation: [ 7.0710677e-01 7.0710677e-01 -7.0710677e-01 7.0710677e-01
0.0000000e+00 -8.6595606e-17 -8.6595606e-17 0.0000000e+00]
Reward: 0.3956568676265005 Done: False
After 9 action -> Observation: [-4.3297803e-17 4.3297803e-17 -4.3297803e-17 -4.3297803e-17
7.0710677e-01 -7.0710677e-01 -7.0710677e-01 -7.0710677e-01]
Reward: 0.9003790168046004 Done: False
After 10 action -> Observation: [ 4.3297803e-17 4.3297803e-17 -4.3297803e-17 4.3297803e-17
7.0710677e-01 7.0710677e-01 7.0710677e-01 -7.0710677e-01]
Reward: 0.17902713357182076 Done: False
After 7 action -> Observation: [ 4.3297803e-17 4.3297803e-17 5.0000000e-01 -5.0000000e-01
7.0710677e-01 7.0710677e-01 5.0000000e-01 -5.0000000e-01]
Reward: 0.013988176329040307 Done: False
After 10 action -> Observation: [-5.00000000e-01 5.00000000e-01 7.39139743e-17 1.26816325e-17
-5.00000000e-01 5.00000000e-01 7.07106769e-01 7.07106769e-01]
Reward: 0.8421284198866531 Done: False
After 13 action -> Observation: [-5.0000000e-01 5.0000000e-01 -7.0710677e-01 -7.0710677e-01
5.0000000e-01 -5.0000000e-01 1.1721177e-16 5.5979435e-17]
Reward: 0.3197259028672091 Done: False
After 9 action -> Observation: [ 8.6595606e-17 8.6595606e-17 5.0000000e-01 -5.0000000e-01
7.0710677e-01 7.0710677e-01 5.0000000e-01 -5.0000000e-01]
Reward: 0.013988176329040366 Done: False
After 8 action -> Observation: [ 5.0000000e-01 -5.0000000e-01 7.0710677e-01 7.0710677e-01
-5.0000000e-01 5.0000000e-01 -5.5979435e-17 -1.1721177e-16]
Reward: 0.31972590286720903 Done: False
After 5 action -> Observation: [ 5.0000000e-01 -5.0000000e-01 -5.5979435e-17 -1.1721177e-16
-5.0000000e-01 5.0000000e-01 -7.0710677e-01 -7.0710677e-01]
Reward: 0.3693943622933696 Done: False
After 4 action -> Observation: [ 5.0000000e-01 -5.0000000e-01 7.0710677e-01 7.0710677e-01
-5.0000000e-01 5.0000000e-01 -5.5979435e-17 -1.1721177e-16]
Reward: 0.31972590286720903 Done: False
After 2 action -> Observation: [-5.5979435e-17 -1.1721177e-16 5.0000000e-01 -5.0000000e-01
-7.0710677e-01 -7.0710677e-01 5.0000000e-01 -5.0000000e-01]
Reward: 0.43404999985939907 Done: False
After 10 action -> Observation: [-5.0000000e-01 5.0000000e-01 -2.5363265e-17 -1.4782795e-16
-5.0000000e-01 5.0000000e-01 -7.0710677e-01 -7.0710677e-01]
Reward: 0.3197259028672091 Done: False
After 13 action -> Observation: [-5.0000000e-01 5.0000000e-01 7.0710677e-01 7.0710677e-01
5.0000000e-01 -5.0000000e-01 -6.8661066e-17 -1.9112575e-16]
Reward: 0.8421284198866528 Done: False
After 3 action -> Observation: [-5.0000000e-01 5.0000000e-01 -7.0710677e-01 -7.0710677e-01
5.0000000e-01 -5.0000000e-01 6.8661066e-17 1.9112575e-16]
Reward: 0.3197259028672089 Done: False
After 6 action -> Observation: [-0.5 0.5 -0.5 -0.5 0.5 -0.5 -0.5 -0.5]
Reward: 0.61765681188712 Done: False
After 12 action -> Observation: [ 0.5 -0.5 0.5 0.5 0.5 -0.5 -0.5 -0.5]
Reward: 0.6556714049540987 Done: False
After 7 action -> Observation: [ 5.0000000e-01 -5.0000000e-01 -1.1102230e-16 -2.2204460e-16
5.0000000e-01 -5.0000000e-01 -7.0710677e-01 -7.0710677e-01]
Reward: 0.8421284198866528 Done: False
After 10 action -> Observation: [ 1.4163847e-16 1.9142844e-16 5.0000000e-01 -5.0000000e-01
7.0710677e-01 7.0710677e-01 5.0000000e-01 -5.0000000e-01]
Reward: 0.013988176329040477 Done: False
After 6 action -> Observation: [ 1.4163847e-16 1.9142844e-16 -2.2204460e-16 1.1102230e-16
7.0710677e-01 7.0710677e-01 7.0710677e-01 -7.0710677e-01]
Reward: 0.1790271335718209 Done: False
After 7 action -> Observation: [ 1.4163847e-16 1.9142844e-16 5.0000000e-01 -5.0000000e-01
7.0710677e-01 7.0710677e-01 5.0000000e-01 -5.0000000e-01]
Reward: 0.013988176329040461 Done: False
After 13 action -> Observation: [ 7.0710677e-01 7.0710677e-01 -5.0000000e-01 5.0000000e-01
-9.8340671e-17 -1.4813063e-16 5.0000000e-01 -5.0000000e-01]
Reward: 0.434049999859399 Done: False
After 0 action -> Observation: [ 0.14644662 0.85355341 0.85355341 0.14644662 0.35355338 -0.35355338
-0.35355338 0.35355338]
Reward: 0.5855835819930668 Done: False
After 7 action -> Observation: [ 0.14644662 0.85355341 0.35355338 0.35355338 0.35355338 -0.35355338
-0.85355341 0.14644662]
Reward: 0.744978975447949 Done: False
After 6 action -> Observation: [ 0.14644662 0.85355341 0.85355341 0.14644662 0.35355338 -0.35355338
-0.35355338 0.35355338]
Reward: 0.5855835819930667 Done: False
After 7 action -> Observation: [ 0.14644662 0.85355341 0.35355338 0.35355338 0.35355338 -0.35355338
-0.85355341 0.14644662]
Reward: 0.744978975447949 Done: False
After 2 action -> Observation: [-0.85355341 0.14644662 -0.35355338 0.35355338 -0.35355338 -0.35355338
0.14644662 0.85355341]
Reward: 0.5902209968381783 Done: False
After 1 action -> Observation: [-0.35355338 0.35355338 -0.85355341 0.14644662 0.14644662 0.85355341
-0.35355338 -0.35355338]
Reward: 0.26833470406567134 Done: True