BlochSphereV1
Description
BlochSphereV1 models the single-qubit Bloch sphere as a finite graph problem for reinforcement learning. Rather than tracking a continuous statevector, the environment works with a discrete set of six canonical pure states — |0⟩, |1⟩, |+⟩, |-⟩, |+i⟩, |-i⟩ — and four deterministic gate actions (H, X, Z, S).
The qubit lives on a directed graph with 6 nodes. Each node is one of the canonical states and each edge represents a gate action that maps one state to another. Because this is a proper finite Markov Decision Process (MDP), BlochSphereV1 is fully compatible with tabular planning algorithms such as ValueIteration and QValueIteration from qrl.algorithms — no wrapper required.
The objective is to steer the qubit from the fixed initial state |0⟩ (index 0) to a user-specified target pure state (default |+⟩, index 2) within a limited number of steps.
Key details
Action space: Discrete(4) — gates H, X, Z, S.
Observation space: Discrete(6) — integer index ∈ {0,1,2,3,4,5} for the six canonical states.
Reward: Binary sparse —
1.0if fidelity ≥reward_tolerance,0.0otherwise.Termination: Success when fidelity ≥
reward_tolerance, truncation atmax_steps.Rendering: 2D state-transition graph with optional agent-model panel showing learned value function and greedy policy.
When to prefer V1 over V0? Use BlochSphereV1 when you want to apply classical RL planning methods (value iteration, Q-value iteration, policy iteration) or when a discrete-state formulation suffices for your experiment. Use BlochSphereV0 for continuous-action experiments or deep-RL training that requires a richer, continuous Bloch-vector observation.
Action Space
The action space is gymnasium.spaces.Discrete(4). Each integer index selects a unitary gate to apply to the current statevector. Gate transitions are deterministic — the same action from the same state always leads to the same next state.
Num |
Action |
Description |
|---|---|---|
0 |
|
Hadamard gate |
1 |
|
Pauli-X (NOT) |
2 |
|
Pauli-Z |
3 |
|
Phase gate (S) |
The full (6 × 4) transition table T[s, a] = s' can be retrieved via the static method BlochSphereV1.transition_table(). This table is also used internally for the graph rendering.
Note:
BlochSphereV1uses only 4 gates vs. the 17 available inBlochSphereV0. The four gates are chosen because they suffice to reach all six canonical states from any starting state and form a clean finite MDP over the canonical Bloch-sphere axes.
Observation Space
The observation is a single integer representing the current discrete state index. Space type: gymnasium.spaces.Discrete(6).
Index |
State |
Description |
|---|---|---|
0 |
|
Computational basis state zero |
1 |
|
Computational basis state one |
2 |
|
Equal superposition (positive phase) |
3 |
|
Equal superposition (negative phase) |
4 |
|
Y-axis positive pole |
5 |
|
Y-axis negative pole |
Auxiliary properties (not part of observation_space but available on the env object):
env.state_index— current state index (same as the returned observation).env.bloch_vector—(x, y, z)float32 array for the current canonical state.BlochSphereV1.transition_table()— static (6, 4) integer array.
Rewards
The reward signal is binary and sparse:
reward = 1.0 if fidelity(current_state, target_state) ≥ reward_tolerance
reward = 0.0 otherwise
where fidelity is |⟨target | current⟩|² and reward_tolerance defaults to 0.99.
This sparse 0/1 signal is well-suited for tabular planning algorithms (e.g. Value Iteration) that propagate rewards backwards through the known transition table. For policy-gradient or Q-learning agents that benefit from denser feedback, consider wrapping the environment and shaping the reward (e.g. by adding a small negative step penalty).
Contrast with V0:
BlochSphereV0returns a continuous fidelity reward in[0, 1]at every step, making it more informative for gradient-based agents.
Starting State
On reset() the environment:
Sets
_state_index = 0(corresponding to|0⟩).Resets the internal statevector to
STATE_VECTORS[0].Clears
historyto[0](only the initial state index).Sets
steps = 0,terminated = False,truncated = False.
The target state is fixed at construction time via the target_state argument (integer index, default 2 = |+⟩). It does not change between episodes.
Episode End
An episode ends when either of the following conditions is met:
Termination (success): Fidelity between the current state and the target state meets or exceeds
reward_tolerance(default0.99).terminated = True.Truncation: The number of steps reaches
max_steps(default10).truncated = True.
step() returns the 5-tuple (observation, reward, terminated, truncated, info) in compliance with the modern Gymnasium API. The info dict contains:
Key |
Type |
Description |
|---|---|---|
|
|
Current fidelity with the target state. |
|
|
Name of the gate applied in this step. |
|
|
Current state index (same as |
Note: Unlike
BlochSphereV0,BlochSphereV1returns a 5-tuple fromstep()(terminated and truncated are separate) and also returnsinfofromreset().
Render
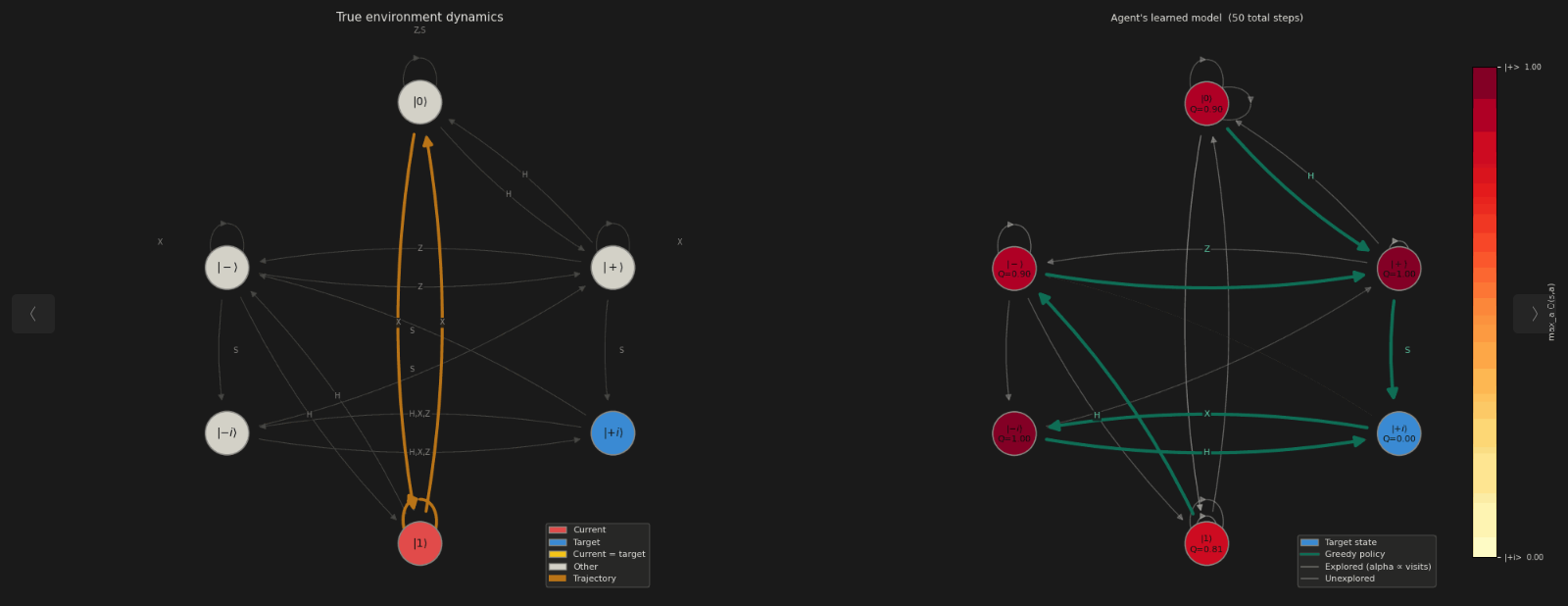
BlochSphereV1 uses a two-step rendering workflow:
Step 1 — Collect frames: env._render_graph(agent, show_true_dynamics=True)
Call this at the end of each training episode. It draws a snapshot of the current state and appends it to env.fig_array_list. The snapshot contains up to two panels:
Left panel (
show_true_dynamics=True, default): True environment dynamics graph.Nodes are coloured: red = current, blue = target, yellow = current=target, grey = other.
Episode trajectory is overlaid in bold orange.
Right panel (requires
agentargument): Agent’s learned model.Node colour encodes V(s) or max_a Q(s,a) on a warm colormap (warm = high value).
Edge opacity is proportional to visit counts.
Bold teal edges show the greedy policy (argmax_a Q(s,a)).
A colorbar labels the minimum/maximum value states.
Raises ValueError if no agent is provided.
Step 2 — Save animation: env.render(save_path_without_extension, interval=600, ffmpeg=False)
Assembles all collected frames into a single .gif (or .mp4 if ffmpeg=True) animation and saves it to <save_path_without_extension>.gif.
Raises ValueError if _render_graph() was never called (no frames collected).
Arguments (Constructor & Reset Options)
Constructor signature:
BlochSphereV1(
target_state: int = 2,
max_steps: int = 10,
reward_tolerance: float = 0.99,
ffmpeg: bool = False,
)
target_state: Target state index in[0, 5]. Default2(|+⟩). Mapping: ``0→|0⟩, 1→|1⟩, 2→|+⟩, 3→|-⟩, 4→|+i⟩, 5→|-i⟩``.max_steps: Maximum actions per episode (truncation threshold). Default10.reward_tolerance: Fidelity threshold for success. Must be in(0, 1]. Default0.99.ffmpeg: IfTrue, animations are saved as.mp4(requires ffmpeg). DefaultFalse(GIF).
reset(seed=None, options=None) accepts an optional seed passed to the Gymnasium base class and always returns (0, info_dict) — the fixed initial state index and its info.
[ ]:
### Example 1 — Standalone random agent
from qrl.env import BlochSphereV1
# Target state is |+⟩ (index 2)
# set ffmpeg=True if you have ffmpeg installed to save as mp4, or ffmpeg=False to save as gif
env = BlochSphereV1(target_state=2, max_steps=10, reward_tolerance=0.99, ffmpeg=False)
# Reset
obs, info = env.reset()
print("Initial state index:", obs) # always 0 → |0⟩
print("Initial info:", info)
print("Bloch vector:", env.bloch_vector)
# Transition table (6 states × 4 actions)
print("\nTransition table (T[s, a] = s'):\n", BlochSphereV1.transition_table())
# Random rollout
action_names = ['H', 'X', 'Z', 'S']
for step in range(env.max_steps):
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
print(f"Step {step+1} | Gate: {action_names[action]:<2} | "
f"State: {obs} | Reward: {reward:.1f} | "
f"Fidelity: {info['fidelity']:.4f}")
if terminated or truncated:
break
print("\nEpisode finished. Env repr:", repr(env))
[ ]:
### Example 2 — Training with ValueIteration + animated graph rendering
from qrl.algorithms.classical import ValueIteration
from qrl.env import BlochSphereV1
# ---- Training and Testing Environment ------
env = BlochSphereV1(target_state=4, max_steps=10, reward_tolerance=0.99)
test_env = BlochSphereV1(target_state=4, max_steps=10, reward_tolerance=0.99)
# ---- Training Agent (ValueIteration Algorithm) ------
agent = ValueIteration(env=env, gamma=0.9)
# ---- Training Loop ------
TEST_EPISODES = 20
iter_no, best_reward = 0, 0.0
while True:
iter_no += 1
agent.play_n_random_steps(50)
agent.value_iteration()
# ---- Save the training progress ------
env._render_graph(agent=agent)
reward = 0.0
for _ in range(TEST_EPISODES):
obs, _ = test_env.reset()
while True:
action = agent.select_action(int(obs))
obs, _, terminated, truncated, info = test_env.step(action)
if terminated or truncated:
reward += float(terminated) # success rate
break
reward /= TEST_EPISODES
print(f"Iteration {iter_no} reward: {reward:.3f}")
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (best_reward, reward))
best_reward = reward
if reward >= 1.0: # 100% success rate
print("Solved in %d iterations!" % iter_no)
break
# ---- Render the training progress ------
env.render(save_path_without_extension="bloch_sphere_value_iteration",
interval=600, ffmpeg=False)
print("Animation saved.")
[1]:
### Example 3 — Training with QValueIteration
from qrl.algorithms.classical import QValueIteration
from qrl.env import BlochSphereV1
# ---- Training and Testing Environment ------
env = BlochSphereV1(target_state=4, max_steps=10, reward_tolerance=0.99)
test_env = BlochSphereV1(target_state=4, max_steps=10, reward_tolerance=0.99)
# ---- Training Agent (QValueIteration Algorithm) ------
agent = QValueIteration(env=env, gamma=0.9)
# ---- Training Loop ------
TEST_EPISODES = 20
iter_no, best_reward = 0, 0.0
while True:
iter_no += 1
agent.play_n_random_steps(50)
agent.qvalue_iteration()
# ---- Save the training progress ------
env._render_graph(agent=agent,show_true_dynamics=True)
reward = 0.0
for _ in range(TEST_EPISODES):
obs, _ = test_env.reset()
while True:
action = agent.select_action(int(obs))
obs, _, terminated, truncated, info = test_env.step(action)
if terminated or truncated:
reward += float(terminated) # success rate
break
reward /= TEST_EPISODES
print(f"Iteration {iter_no} reward: {reward:.3f}")
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (best_reward, reward))
best_reward = reward
if reward >= 1.0: # 100% success rate
print("Solved in %d iterations!" % iter_no)
break
# ---- Render the training progress ------
env.render(save_path_without_extension="bloch_sphere_qvalue_iteration",
interval=600, ffmpeg=False)
print("Animation saved.")
Iteration 1 reward: 1.000
Best reward updated 0.000 -> 1.000
Solved in 1 iterations!
Animation saved.
Implementation Notes & Extensions
Transition table: The environment pre-computes a
(6, 4)integer array_TRANSITIONS(imported fromqrl.env.utils) where_TRANSITIONS[s, a] = s'. This table is also used for graph construction in the render methods. To inspect it:BlochSphereV1.transition_table().Algorithm compatibility:
ValueIterationdetects the value function via the attributeagent._V, whileQValueIterationis detected viaagent._Q. The render panel usesmax_a Q(s, a)when a Q-table is present andV(s)otherwise.Adding more states / actions: Extending V1 to a richer gate set (e.g. adding T or Y gates) requires updating
ACTION_NAMES,GATES, and_TRANSITIONSinutils.py, and adjustingaction_space = spaces.Discrete(N)accordingly.Reward shaping: For model-free agents, add a small step penalty (e.g.
−0.01) insideget_reward()to encourage shorter paths. The commented-outSTEP_PENALTYandSUCCESS_BONUSconstants in the source are a natural starting point.Rendering only the agent panel: Pass
show_true_dynamics=Falseto_render_graph()to omit the left panel and render only the agent’s learned model.Multiple target states: Wrap the environment in a meta-loop that instantiates
BlochSphereV1with differenttarget_statevalues to train a goal-conditioned agent.
Version History
v1: Discrete graph formulation of the Bloch sphere. Six canonical states, four deterministic gate actions (H, X, Z, S). Integer observation, binary sparse reward. Fully compatible with
ValueIterationandQValueIterationfromqrl.algorithms. Two-step 2D graph-based renderer with agent-model panel (value colormap + greedy policy overlay). Returns 5-tuple(obs, reward, terminated, truncated, info)fromstep()in line with modern Gymnasium API.v0: Initial design and implementation. Single-qubit pure-state environment with fixed initial state
|0⟩, discrete gate set, fidelity reward, Matplotlib-based Bloch sphere renderer, and history tracking.
References (Suggested Reading)
Bloch sphere — standard geometric representation for a single qubit.
Nielsen, M. A., & Chuang, I. L., Quantum Computation and Quantum Information (for unitary gate definitions and single-qubit geometry).
Sutton, R. S., & Barto, A. G., Reinforcement Learning: An Introduction (2nd ed.) (for Value Iteration, Q-Value Iteration, and finite MDP fundamentals).